2025-06-10 17:00:47雷霆软件园
在2025年高考数学科目考试结束后,网络上关于试卷难度的讨论热度不减。作为科技领域的观察者,我们不禁好奇,对于当前备受瞩目的AI技术而言,这份数学试卷是否同样具有挑战性?为了回答这个问题,我们组织了一场特别的“考试”,邀请了多家知名的大模型参与,模拟完成了一套高考数学试卷。
本次“考试”中,我们挑选了以下几家具有代表性的大模型作为“考生”:DeepSeek R1 0528、通义千问 Qwen3-235B-A22B、讯飞星火 X1-0420、豆包 Seed-Thinking-v1.5、文心 X1 Turbo、腾讯混元 Hunyuan T1 latest和GPT o3。由于网络流传的试题版本不一,我们通过多版本交叉验证和教师解题验证的方式,确保评测的准确性,试卷总分为150分。
我们特别邀请了一位拥有十年高中数学教研经验的专家汪鹏老师,对大模型的答案进行评分。考虑到部分模型在OCR识别方面的限制,我们采用了OCR转写后输入答题的方式进行处理。
接下来,让我们通过几道典型题目,看看这些大模型的表现如何。
首先是选择题第一题,各家大模型均给出了正确答案,显示出它们在基础题目上的稳定表现。
选择题第五题是一道涉及函数的题目,所有大模型再次全部答对,进一步证明了它们在复杂题目上的解题能力。
然而,在选择题第八题中,豆包大模型和DeepSeek出现了错误,而其他模型均给出了正确答案。这道题目涉及对数函数,显示出部分模型在处理特定数学知识点时的局限性。
在解答题方面,我们以第16题为例,这是一道涉及数列和函数的题目。DeepSeek、通义千问、讯飞星火和豆包大模型均给出了正确的解题过程和答案,而文心X1和腾讯混元则出现了不同程度的错误。
最后,我们来看难度更高的第18题。讯飞星火、豆包大模型、DeepSeek、通义千问和GPT o3均获得了满分,而文心X1则因答案错误而失分。
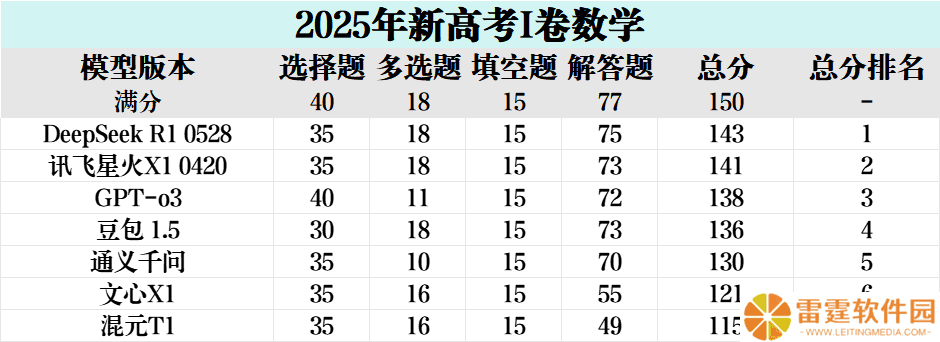
经过综合评分,DeepSeek以143分的成绩位列榜首,讯飞星火以141分紧随其后,GPT o3以138分获得第三名。这次“考试”不仅展示了AI在数学领域的强大能力,也暴露了部分模型在实际应用中的短板。
DeepSeek作为最新版本的大模型,在思考推理和数学能力方面表现出色,但OCR识别效果不佳,且推理速度慢、资源消耗高。讯飞星火则凭借其较小的模型量级和高效的数学能力,在评测中取得了优异成绩,显示出其在教育领域的深厚积累。
豆包和通义千问等大模型也表现出色,与国际顶尖模型水平相当。这次“考试”不仅是对AI数学能力的一次检验,更是对未来AI在教育领域深度应用的一次探索。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表本站立场。文章及其配图仅供学习分享之
新品榜/热门榜